How I thought through the log package design before writing any code

Here's what clicked.
Understanding the structure of a log is one aspect of learning curve. And sitting down to build it in Go is a whole different trajectory! Here's how the progression looked.
Step 0: Co-relations; Why logs matter
Logs are not optional in production. Obviously.
If something breaks at scale especially in a distributed system logs are often the only source of truth. No logs means no debugging, no replay, no visibility and the most nerve-gutting on-calls of your life. How do you even begin to understand a system you can't observe?
That naturally lead to a fundamental question:
What is a log under the hood?
At first glance, a log looks like “just writing to a file”. That's what I thought when I was building log rotations at earlier gigs and technically it's not wrong. You do write to a file. But how do these things need to work?
Step 1: Understand what the system actually needs to do
How do these things need to work at the business logic level first then move onto the code level.
A log needs to be append-only. Why? Because you can never edit past(if only it were possible. :P). Immutability is what makes replication safe, recovery simple, and debugging possible. The moment you allow mutation, you lose the guarantee ex: offset 42 always means the same thing.
Why log needs offset? a non-negative position index. Why non-negative? Because offset represents a position in a sequence that only grows forward. You can never have a record at position -1. The constraint reflects the reality of how the data moves.
These are some business requirements expressed as code constraints/design precisions. Getting clear on the why before the how means the code structure almost suggests itself. Read on uint64, fun fact
Curious: Why not just keep writing to single file? I use tail -f and grep on log files all the time while debugging. Why do I do that? Because the content is there sequential, readable. But writing everything into a single file is disaster:
- File grows indefinitely and is hard to manage
- Reads become slower and is scanning from the start every time
- Compaction and deletion become painful
- Recovery becomes expensive
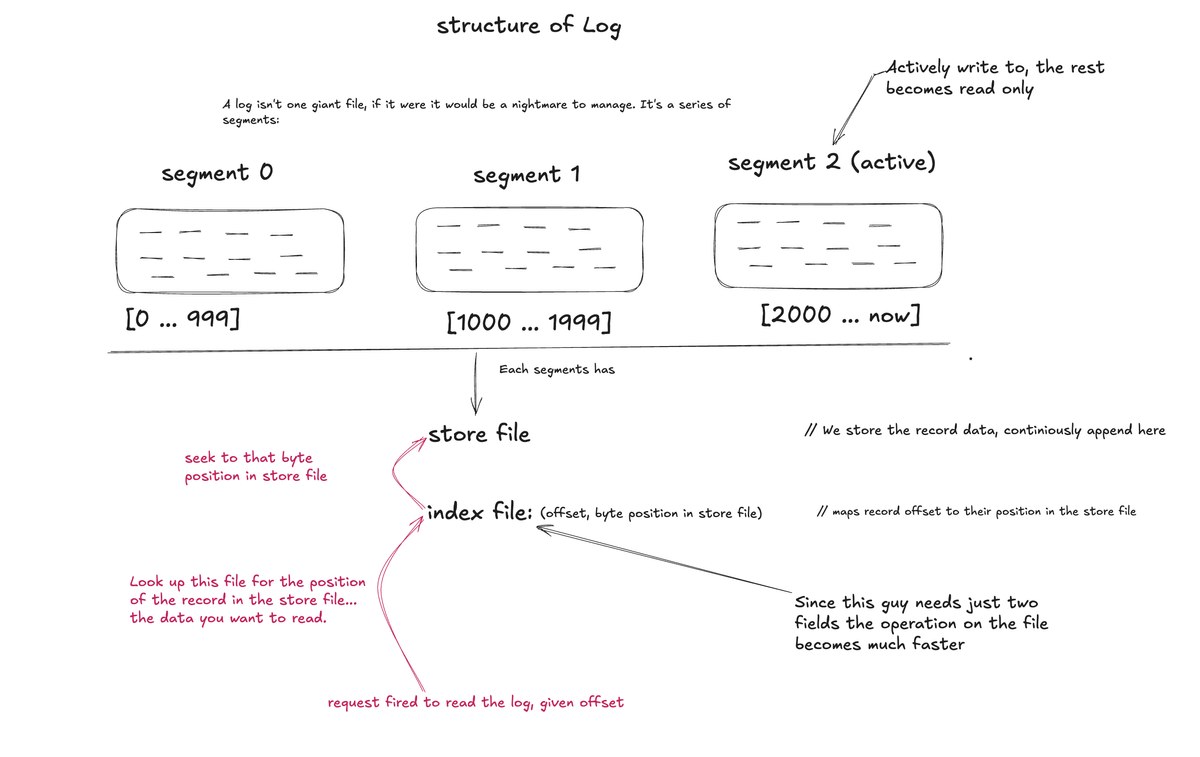
Makes so much sense! Go through the image on structure of Log or tweet.:
From the image it's quite clear that a log is a series of segments. And the index is what makes reads fast. Without it, finding offset X (say 1500) means scanning from byte 0. With it, you jump directly to the right byte position, this is the same principle as a database index.
Step 2: Understand the flow before picking packages
Once I knew what the system needed to do, I started thinking about the flow.
Write, append, read, open, close these are the actionable operations on a file in relative to what is needed for this system to be built. And every one of them involves I/O. Which means every one of them crosses from my Go program into the kernel.
That's when the os package started to look like what it actually is: a thin wrapper around syscalls. When you see os.OpenFile, os.Write, os.Read these are thin wrappers around syscalls. Every one of them crosses the boundary from your Go program into the kernel i.e user space to kernel space.
This is the moment the flow became concrete for me:
my Go code → os package → syscall → kernel → diskEach hop has a cost. And that cost compounds at scale. So the question shifted from "how do I write to a file" to "how do I design around the cost of writing to a file."
Syscalls are not free, they involve a context switch from user space to kernel space. What is the price we pay?
Step 3: Ask the core design question
Who is touching this file, when, and how many of them at once?
These questions unlocks the concurrency design.
Single writer, no readers: trivial. Open, append, close. No coordination needed.
Multiple readers, no writer: safe. Reads don't mutate state. Everyone can read simultaneously without stepping on each other.
One writer + multiple readers: now there's a problem. If a goroutine is mid-write while another reads, it might see partial data. Torn reads. Corruption in perception even if not on disk.
Multiple writers: chaos. Two goroutines appending simultaneously means interleaved bytes. The file becomes garbage.
further read when to use mutex (for concurrency)
Step 4: Design layers with single responsibilities
Once I understood the concurrency question, the layering defined in the book became obvious.
The log package has to handle: durable writes, fast reads, concurrent access, and eventually compaction. That's too much for one type. You split it.
Each layer gets one job:
store: owns raw byte I/O. Knows nothing about offsets.index: owns offset → position mapping. Knows nothing about bytes.segment: composes store + index. Knows about one chunk of the log.log: owns all segments. Handles concurrency at the top.
Single responsibility makes each piece independently testable, independently replaceable, reasonably simple to reason about and make it reliable. When something breaks in production you need to know which layer broke... in any system.
understand log package layers with example
Step 5: Push concurrency to the top layer
This one is subtle to connect dots.
Concurrency is managed at the log level. The log owns the Mutex. Every layer below it is single-threaded by contract.
Why? Because if concurrency is scattered across layers, you get lock ordering bugs, deadlocks, and races that are nearly impossible to reason about. When it lives in one place, you reason about it in one place.
The log guarantees: only one writer or multiple readers reach the layers below at any given time. The layers below trust that guarantee and don't think about it.
Step 6: Minimize what will hurt at scale
Two specific things to minimize:
understand the The cost of a syscall
Syscalls: batch writes with bufio.Writer. Eliminate index read syscalls entirely with mmap. One extra syscall per record is invisible at 100 records. At 10 million records per second it's the difference between a system that holds and one that falls over.
Lock contention: RWMutex instead of plain Mutex precisely because reads vastly outnumber writes in most log workloads. Multiple readers proceed in parallel. Only writes block.
Step 7: Test persistence explicitly
Writing tests cases is an art itself which am learning to do so.
The mental map
Before writing any system that touches files under concurrency:
→ understand the business constraints first (why append-only? why non-negative offsets?)
→ trace the full flow from your code to disk
→ ask who touches the data and when
→ let the access pattern determine the synchronization primitive
→ design layers with single responsibilities
→ push concurrency ownership to the top layer
→ minimize syscalls through buffering and memory mapping
→ test persistence explicitlyThis isn't specific to a log package. This pattern is familiar to every system that touches shared mutable state.