Understand log package layers

Part of the Building the Log Package series How I thought through the log package design before writing any code
The five layers of the log package are easiest to understand by tracing one record through all of them.
The scenario
Building a chat app. Messages come in:
"hello" → offset 0
"world" → offset 1
"foo" → offset 2Let's trace what happens to "hello" at every layer.
1. Record
A record is just the raw data you want to store. Nothing fancy.
"hello" as bytes → [104 101 108 108 111]But in practice a record is slightly more than just the bytes. It's the bytes plus a length prefix so the store knows where one record ends and the next begins.
[0 0 0 0 0 0 0 5] [104 101 108 108 111]
↑ length ↑ actual "hello"This is called length-prefixed encoding. Without it, how would you know if you're reading one 10-byte record or two 5-byte records? You wouldn't. The length prefix makes boundaries explicit.
Think in code: a record is []byte. The length prefix is handled by the store when writing.

2. Store
The store is a file on disk. Its only job is: given bytes, append them. Given a position, read bytes from there. It knows nothing about offsets, nothing about what the bytes mean. Just raw I/O.
After writing "hello", "world", "foo" the store file looks like:
position 0 → [0 0 0 5][hello] // 13 bytes total (8 for length + 5 for data)
position 13 → [0 0 0 5][world]
position 26 → [0 0 0 3][foo]The store hands back the position of each write. That position is the only thing it cares about returning. It says "I wrote your bytes at position 13" and forgets about it.
Think in code: store has two methods essentially Append([]byte) (position, error) and Read(position) ([]byte, error). In the code it wraps an os.File with a bufio.Writer to batch syscalls.
Why the decision bufio.Writer and not direct os.File writes?
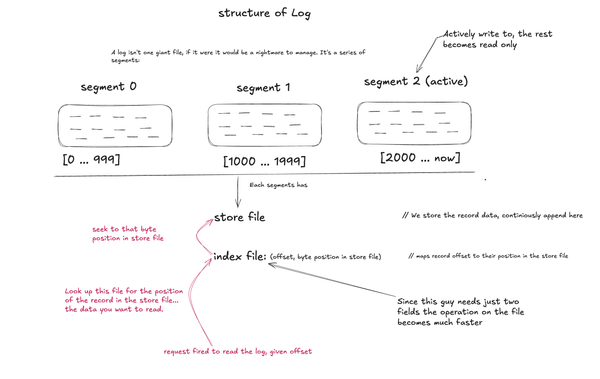
3. Index
The index is a separate file. Its only job is: map logical offset → byte position in the store.
After those three writes:
offset 0 → position 0
offset 1 → position 13
offset 2 → position 26Each entry is fixed width always the same number of bytes regardless of record size. Because entries are fixed width, finding offset N is just O(1).:
byte position in index = N × entry_sizeUnderstand this math with an example
Think of a parking lot where every parking spot is exactly the same size 10 feet wide. If someone says "go to spot number 3", you don't walk past spot 0, check its size, walk past spot 1, check its size... You just calculate:
spot 3 starts at = 3 × 10 feet = 30 feet from the entranceJump straight there. Now imagine a parking lot where every spot is a different size. Compact cars, SUVs, trucks all mixed randomly. To find spot 3 you must walk past 0, measure it, walk past 1, measure it, walk past 2, measure it... only then do you arrive at 3. That's O(n) scanning.
The index uses the parking lot trick. Every entry is fixed width let's say 16 bytes (8 bytes for offset + 8 bytes for position). Always. Regardless of whether the actual record in the store is 5 bytes or 5 megabytes.
entry 0 lives at: 0 × 16 = byte 0 in index file
entry 1 lives at: 1 × 16 = byte 16
entry 2 lives at: 2 × 16 = byte 32
entry N lives at: N × 16 = byte N*16So "give me offset 1500" becomes:
jump to byte 1500 × 16 = 24000 in the index file
read 16 bytes there
extract the store position
doneThe fixed width is what makes this possible and why the index entries must never store variable-length data.
This file is memory-mapped (mmap). The OS maps the index file directly into your process memory. Reading from it is a memory access, not a syscall nor kernel crossing, but a pointer arithmetic.
Think in code: index has Write(offset, position) and Read(offset) (position, error). Internally it's a memory-mapped byte slice.
4. Segment
The segment owns one store file and one index file together. It's the bridge.
When you say "give me offset 1", the segment knows what to do:
1. ask index: "what's the byte position for offset 1?"
→ index says: position 13
2. ask store: "read bytes at position 13"
→ store says: "world"The segment also knows its base offset the first offset it owns. Segment 0 might own offsets 0-999, segment 1 owns 1000-1999. When looking up offset 1500 in segment 1, it translates to index entry 1500 - 1000 = 500 relative offset within that segment. When the segment's store or index hits a configured max size, it's full. It becomes read-only. Time for a new segment.
This is called rolling. The log detects the active segment is full, closes it (marking it read-only), creates a new segment with nextOffset as its base, and makes that the new active. The old segment stays in the segments slice for reads. The new one takes all writes. This happens transparently callers of log.Append never see it.
Think in code: segment composes *store and *index. Its Append and Read methods coordinate between them. It tracks baseOffset and nextOffset.
5. Log
The log owns all segments. It's the public face of the whole system.
[segment 0: offsets 0-999] [segment 1: offsets 1000-1999] [segment 2: active]When a write comes in, it goes to the active segment. When the active segment is full, log creates a new one. When a read comes in for offset 1500, log figures out which segment owns that offset and delegates.
The log also owns the sync.RWMutex. Concurrency is managed here, at the top. Every layer below is single-threaded by contract the log guarantees only one writer or multiple readers reach them at a time.
Think in code: log holds a []*segment slice and a pointer to activeSegment. It owns the sync.RWMutex. Its Append acquires a write lock, delegates to the active segment, and rolls to a new segment when the active one is full. Its Read acquires a read lock, finds the right segment by offset range, and delegates. Concurrency lives here and nowhere else.